|
|
|

Consideracion de la flexibilidad conformacional molecular en los estudios QSAR
|
Quizá la ambición más grande de los químicos teóricos es poder predecir el comportamiento de cualquier sustancia en cualquier entorno. Naturalmente, para satisfacer dicha ambición haría falta un nivel de teoría enormemente elevado, que permita unificar todas las observaciones experimentales habidas y por haber; es sabido que actualmente nos encontramos muy lejos del mismo.
Agregado: 12 de JUNIO de 2012 (Por Eduardo Castro) | Palabras: 10370 | Votar | Sin Votos | Sin comentarios | Agregar Comentario
Categoría: Apuntes y Monografías > Química >
Material educativo de Alipso relacionado con Consideracion flexibilidad conformacional molecular los estudios QSAR
Enlaces externos relacionados con Consideracion flexibilidad conformacional molecular los estudios QSAR
Autor: Eduardo Castro (eacast@gmail.com)
 Este apunte fue enviado por su autor en formato DOC (Word).
Para poder visualizarlo correctamente (con imágenes, tablas, etc) haga click aquí o aquí si desea abrirla en ventana nueva. Este apunte fue enviado por su autor en formato DOC (Word).
Para poder visualizarlo correctamente (con imágenes, tablas, etc) haga click aquí o aquí si desea abrirla en ventana nueva. |
CONSIDERACI�N DE LA FLEXIBILIDAD CONFORMACIONAL MOLECULAR EN LOS ESTUDIOS QSAR
Javier Garc�a, Pablo R. Duchowicz, Eduardo A. Castro*
INIFTA, Divisi�n Qu�mica Te�rica, CONICET-Universidad Nacional de La Plata, Suc.4, C.C. 16, 1900, La Plata
![]()
* Autor correspondiente (eacast@gmail.com)
1 �Introducción
Quizá la ambición más grande de los químicos teóricos es poder predecir el comportamiento de cualquier sustancia en cualquier entorno. Naturalmente, para satisfacer dicha ambición haría falta un nivel de teoría enormemente elevado, que permita unificar todas las observaciones experimentales habidas y por haber; es sabido que actualmente nos encontramos muy lejos del mismo.
�Hoy en día, nuestros mayores esfuerzos recaen en la aplicación de la mecánica cuántica a sistemas químicos compuestos por algunas pocas moléculas; esto permite elucidar la estructura de los mismos en estado estacionario, e incluso su evolución espacio-temporal. Para ello, se requiere resolver la ecuación de Schr�dinger teniendo en cuenta tres grados de libertad por cada partícula que conforma el sistema. Por esta razón, los cálculos necesarios se vuelven muy costosos para sistemas relativamente pequeños, como pueden ser los átomos pesados, e inimaginablemente costosos para sistemas formados por cantidades de moléculas del orden del número de Avogadro.
�Sin embargo, contamos con un enorme número de medidas experimentales de todo tipo reportadas en literatura: pesos moleculares, momentos dipolares, puntos de fusión y ebullición, variables termodinámicas (entropías, entalpías, energías libres), constantes de velocidad de reacción, etc.
La teoría QSAR/QSPR (Relaciones Cuantitativas Estructura-Actividad / Relaciones Cuantitativas Estructura-Propiedad) surge de la necesidad de predecir distintas propiedades de los sistemas químicos sin recurrir a la descripción cuántica de los mismos[1,2,3].
�Dicha teoría se basa en la idea de que las propiedades de una sustancia están relacionadas cuantitativamente con la estructura de las moléculas que la componen; de esta manera, el problema de tratar cuánticamente al sistema químico se reduce a encontrar la relación matemática entre la estructura de sus moléculas y la propiedad que se quiere estudiar. Este procedimiento está resumido en la figura 1.1.1.

Figura 1.1.1: Representación gráfica del problema QSAR/QSPR
�Para llegar a tal fin, como primer paso es necesario precisar a qué nos referimos cuando hablamos de estructura molecular; luego, encontrar una manera de describirla matemáticamente, y finalmente, encontrar la relación cuantitativa que existe entre dicha descripción y la propiedad en estudio. En esta sección procederemos a describir cada uno de estos pasos.
1.1.1 �Diferencia entre QSAR y QSPR
QSPR es un término que se aplica a la predicción de propiedades, como pueden ser, por ejemplo, solubilidad en agua, coeficientes de partición, índices de retención cromatográficos, etc.[1]. Muchas veces, estas propiedades dependen de características simples de la estructura molecular.
�Si la propiedad que se trata de predecir es una actividad biológica, el problema toma otra dimensión. En este caso, la actividad de un compuesto depende no solo de su estructura sino también de las propiedades del receptor con el que interactúe. Debido a esta complicación, los estudios de actividad biológica se consideran aparte bajo el nombre de QSAR.
�Debido a la notable influencia de la estructura del receptor en el valor numérico de la actividad biológica que se estudia, se pueden distinguir dos tipos de metodologías en QSAR: las independientes de alineamiento y las dependientes de alineamiento. En ambas variantes, se centra la atención en la estructura del ligando, con la diferencia de que en la primera, dicha estructura se modela teniendo en cuenta la interacción con el receptor, mientras que en la segunda la estructura que se representa es independiente del mismo[?].
Por estructura molecular se entiende la disposición en el espacio de los átomos que componen la molécula. Es posible visualizar la estructura a través de modelos de esferas y barras habitualmente usados en Química. Esta definición parece muy sencilla, pero en realidad no lo es desde el punto de vista teórico. Por ejemplo, si recurrimos a la aproximación de Born-Oppenheimer, la estructura molecular queda determinada por las posiciones de equilibrio de los núcleos que conforman a la molécula y la función de onda electrónica. Si recurrimos a la descripción mediante orbitales moleculares, la función de onda electrónica queda dividida en varias funciones de onda; una para cada electrón. También podemos usar modelos más sencillos, sin recurrir a cálculos de ningún tipo, como aquellos que se usan para describir compuestos orgánicos e inorgánicos (figura 1.2.1) . Es notable que aún sin realizar ningún tipo de cálculos, muchas veces podemos comparar propiedades de las moléculas; por ejemplo, cualquier libro de química orgánica nos confirmará que, de entre los dos compuestos de la figura 1.2.2, el punto de fusión del de la izquierda es menor, ya que posee mayor impedimento estérico para que sus moléculas se alineen. También se puede deducir que el isómero cis posee momento dipolar, mientras que el trans no.

Figura 1.2.1: Representaciones sencillas del benceno y del 2-buteno.

Figura 1.2.2: El trans-2-buteno (izquierda) posee un punto de fusión menor que el cis-2-buteno.
A las representaciones de las figuras 1 y 2 se las denomina grafos: son redes que reflejan las relaciones de contenido y adyacencia de sus componentes[5]. La información que se obtiene de los mismos es la topología de la molécula; es decir, su esqueleto. Dicha representación solo es válida para estudiar propiedades que dependan de las uniones entre los átomos que conforman a la molécula, pero no podríamos estudiar, por ejemplo, momentos dipolares, ya que estos dependen de su estructura tridimensional.
�Para cualquiera de las aplicaciones QSAR, se pueden usar distintas representaciones de la estructura molecular; lo más usual es usar la disposición tridimensional de los átomos en el espacio (en el llamado QSAR 3D), y las representaciones mediante grafos (QSAR 2D).
La descripción de las moléculas es la transformación de la información que contiene la representación de su estructura en variables, a las cuales llamamos descriptores. Dichas variables se pueden definir en función de la representación estructural que se adopte. De esta manera, surge el concepto de dimensionalidad de los descriptores, y podemos clasificar a los mismos según este criterio:
�� 0D: Son los llamados descriptores constitucionales. Tienen en cuenta a la molécula como un todo y solo obtienen información de su fórmula molecular. Un ejemplo de ello puede ser el peso molecular, o la cantidad de átomos de oxígeno.
�� 1D: Tienen en cuenta fragmentos de la molécula, por lo cual se requiere disponer de la fórmula molecular semidesarrollada. Como ejemplo, podríamos citar al número de grupos sulfato, o a la presencia o ausencia de anillos aromáticos.
�� 2D: Los descriptores 2D están basados en la topología molecular, es decir, en la conectividad de los átomos que componen la molécula. Ejemplos típicos son los índices de Wiener y los índices de conectividad molecular[5,6].
�� 3D: Tienen en cuenta los aspectos conformacionales de la estructura molecular; para ello se requiere que las representaciones estructurales describan la posición espacial de los núcleos atómicos que conforman la molécula. Dicha representación requiere de cálculos computacionales previos, ya que la disposición espacial de los núcleos debe ser coherente. Algunos ejemplos son los descriptores WHIM, GETAWAY y los 3D-MoRSE[7].
En la actualidad, para el cálculo de los descriptores se emplean programas muy eficientes que permiten obtener, en poco tiempo, miles de descriptores; algunos de ellos son DRAGON[8], RECON[9], Coral[10] y CoDESSA[11]
Al tener en cuenta la interacción del compuesto en estudio (el ligando) con el receptor se podría decir que se le está agregando una dimensión al problema. La misma consiste en determinar cuál es la mejor manera de tener en cuenta los distintos confórmeros (o de elegir criteriosamente alguno de ellos) a la hora de predecir el valor de la actividad que se está estudiando. A las metodologías que incluyen esta consideración se las engloba en el campo de QSAR 4D. Este tipo de metodologías requiere conocer la estructura del receptor.
�Si uno desea analizar la interacción entre el ligando y un receptor de manera global, debe tener en cuenta las interacciones entre ellos; es decir, la estructura tridimensional de ambos se ve modificada por la interacción. La consideración de dicha interacción está englobada dentro del llamado QSAR 5D[12]. Además de requerir información acerca de la estructura del receptor, este tipo de metodologías requiere modelar la interacción del mismo con los ligandos (lo cual puede llegar a ser muy costoso computacionalmente).
Luego de haber calculado los descriptores, lo que queda es crear el modelo que permita emplear dichos descriptores para predecir el valor numérico de cierta propiedad (o actividad). La tarea consiste en elegir, de entre todos los descriptores que se calcularon o se pueden calcular, los más representativos; es decir, los que posean mayor poder predictivo. Luego resta encontrar la relación matemática entre dichos descriptores y la propiedad que mejor ajuste. Esta tarea no es sencilla, y requiere tener en cuenta muchas variables.
�Para obtener un modelo predictivo se requieren dos conjuntos: el conjunto de calibración (cal) y el conjunto de validación (val). Es necesario conocer el valor experimental de la propiedad que se estudia en ambos conjuntos. El conjunto de calibración se usa para generar el modelo. Sobre él se realizan todas las pruebas necesarias para elegir los descriptores que mejor ajusten al valor experimental de la propiedad. Luego se emplean dichos descriptores para calcular el valor de la propiedad de las moléculas que conforman el conjunto de validación. Si el valor calculado se aproxima en buena medida al experimental para todas las moléculas del conjunto de validación (o por lo menos, la mayoría), significa que el modelo tiene poder predictivo y, en principio, se puede usar para predecir valores de la propiedad en conjuntos nuevos. Esta tarea está resumida en la figura 1.4.1.
Es importante destacar que, por lo general, los modelos que se crean tienen poder predictivo solo cuando son aplicados a moléculas cuya estructura es similar a la de aquellas que se usaron en el conjunto de calibración.

Figura 1.4.1: Esquema general del desarrollo de un modelo QSAR (Traducido de Int. J. Mol. Sci. 2010, 11, página 3848)
Es muy fácil perderse entre los conceptos que se exponen en este trabajo; por ese motivo, resulta necesario desarrollar una notación práctica.
�Al conjunto total de descriptores calculados
le asignaremos la matriz ![]() �a la cual
definimos como:
�a la cual
definimos como:
 (1.1)
(1.1)
![]() �representa el número de moléculas y
�representa el número de moléculas y
![]() �el número de
descriptores del conjunto. Los elementos de matriz
�el número de
descriptores del conjunto. Los elementos de matriz ![]() �representan al
descriptor
�representan al
descriptor ![]() �calculado para
la molécula
�calculado para
la molécula ![]() . Las dimensiones de esta matriz son
. Las dimensiones de esta matriz son ![]() .
.
�Con la letra ![]() �nos referiremos
a los descriptores que conforman un modelo, y con
�nos referiremos
a los descriptores que conforman un modelo, y con ![]() �al valor de la
propiedad predicho por el modelo. Se definen de la siguiente manera:
�al valor de la
propiedad predicho por el modelo. Se definen de la siguiente manera:
 (1.2)
(1.2)
�Los elementos ![]() �representan al
descriptor
�representan al
descriptor ![]() �perteneciente
al modelo calculado para la molécula
�perteneciente
al modelo calculado para la molécula ![]() ;
; ![]() �se refiere al
número de descriptores del modelo, y
�se refiere al
número de descriptores del modelo, y ![]() �al número de
moléculas. (notemos que todos los elementos de
�al número de
moléculas. (notemos que todos los elementos de ![]() �están incluidos
en
�están incluidos
en ![]() ). Las dimensiones de
). Las dimensiones de ![]() �son
�son ![]() . Los elementos
. Los elementos ![]() �representan el
valor de la propiedad calculado para la molécula
�representan el
valor de la propiedad calculado para la molécula ![]() .
.
�También resultará útil descomponer a la matriz
![]() �en vectores
columna;
�en vectores
columna;
![]() (1.3)
(1.3)
�donde
 (1.4)
(1.4)
�El modelo matemático que se obtiene da la relación:
![]() (1.5)
(1.5)
�Para referirnos al valor experimental de la
propiedad, usamos ![]() , la cual está definida como:
, la cual está definida como:
 (1.6)
(1.6)
donde ![]() �representa el
valor experimental de la propiedad de la molécula
�representa el
valor experimental de la propiedad de la molécula ![]() .
.
De todos los modelos que se pueden crear, los más simples son los lineales. Estos establecen una relación del tipo
![]() (1.7)
(1.7)
�o, de manera equivalente,
![]() (1.8)
(1.8)
�Con ![]() . Los
. Los ![]() �son los
coeficientes resultantes del ajuste de cuadrados mínimos.
�son los
coeficientes resultantes del ajuste de cuadrados mínimos.
�Este tipo de modelos son ampliamente usados debido a que son fáciles de obtener, pero también son muy buenos ya que, en general, sobreajustan menos al conjunto de calibración que otros métodos[13].
�En este tipo de modelos (a los que generalizaremos con el nombre de QSAR lineal), encontrar el modelo más predictivo es equivalente a encontrar la ecuación del tipo de (1.7) que arroje una menor desviación estándar, tanto si es aplicada al conjunto de calibración como al de validación[14]; dicho parámetro está definido como:
 (1.9)
(1.9)
�donde ![]() �es el número de
moléculas en el conjunto (puede ser el de calibración o el de validación),
�es el número de
moléculas en el conjunto (puede ser el de calibración o el de validación), ![]() �es el número de
descriptores del modelo y
�es el número de
descriptores del modelo y ![]() �es la
diferencia entre el valor de la propiedad predicho y el experimental para la
molécula
�es la
diferencia entre el valor de la propiedad predicho y el experimental para la
molécula ![]() .
.
�Elegir el modelo que mejor prediga el valor de
una propiedad en un conjunto de moléculas implica crear varios modelos y
calcular ![]() �del conjunto de
calibración y validación (
�del conjunto de
calibración y validación (![]() �y
�y ![]() �respectivamente) para cada uno de ellos, luego
quedarse con el que posea un menor valor de dicha variable. A simple vista esto
no parece complicado, pero, como describiremos a continuación, el número de
regresiones a realizar es demasiado grande como para poder analizar todas las
combinaciones de descriptores.
�respectivamente) para cada uno de ellos, luego
quedarse con el que posea un menor valor de dicha variable. A simple vista esto
no parece complicado, pero, como describiremos a continuación, el número de
regresiones a realizar es demasiado grande como para poder analizar todas las
combinaciones de descriptores.
�Búsqueda exacta
Conceptualmente, la opción más simple es probar todas las combinaciones de descriptores. El número de regresiones lineales que se debe realizar para tal fin está dado por la siguiente fórmula:
![]() (1.10)
(1.10)
�donde ![]() �es el número
total de descriptores y
�es el número
total de descriptores y ![]() �es el número de
descriptores que contiene el modelo. La tabla 1.4.1 muestra una estimación del
tiempo que demora realizar todas estas regresiones usando 1500 descriptores (en
la actualidad, DRAGON calcula más de 1500); a partir de la misma, podemos
concluir que es inviable realizar una búsqueda exacta de modelos de más de tres
descriptores. Por esta razón surgieron varios métodos que intentan explorar el
espacio de descriptores sin realizar todas las regresiones. De ellos,
mencionaremos los que son relevantes para este trabajo.
�es el número de
descriptores que contiene el modelo. La tabla 1.4.1 muestra una estimación del
tiempo que demora realizar todas estas regresiones usando 1500 descriptores (en
la actualidad, DRAGON calcula más de 1500); a partir de la misma, podemos
concluir que es inviable realizar una búsqueda exacta de modelos de más de tres
descriptores. Por esta razón surgieron varios métodos que intentan explorar el
espacio de descriptores sin realizar todas las regresiones. De ellos,
mencionaremos los que son relevantes para este trabajo.
|
|
|
Horas |
|
1 |
|
|
|
2 |
|
�0,45 |
|
3 |
|
|
|
4 |
|
|
|
5 |
|
|
|
6 |
|
|
|
7 |
|
|
|
8 |
|
|
Tabla 1.4.1: Número de regresiones a realizar y tiempo estimado en un procesador Intel Core 2 Quad de 2,7 gHz, corriendo MATLAB 7 bajo Debian GNU/Linux 6.0.3. (aproximadamente 700 regresiones lineales por segundo, 1500 descriptores, 100 moléculas)
Inclusión de a pasos (SI)
El método de inclusión de a pasos (SI) es clásico en el campo QSAR/QSPR. Su popularidad se debe a que representa un procedimiento rápido, sencillo y se halla disponible en cualquier paquete computacional comercial[15].
�El mismo consiste en agregar, en cada paso, la
variable que tenga mayor impacto en la desviación estándar[16]; primero se
elige el descriptor que mejor ajuste a los datos (![]() ). El modelo inicial es
). El modelo inicial es
![]() (1.11)
(1.11)
�En el paso siguiente, se añade otro descriptor
(![]() ), y el modelo resultante es
), y el modelo resultante es
![]() (1.12)
(1.12)
�El descriptor ![]() �se elige de
manera que sea el que menor desviación estándar arroja cuando se lo combina con
�se elige de
manera que sea el que menor desviación estándar arroja cuando se lo combina con
![]() . Los superíndices (1) y (2) indican que los
coeficientes cambian en cada paso.
. Los superíndices (1) y (2) indican que los
coeficientes cambian en cada paso.
�Este criterio se utiliza para agregar varios
descriptores al modelo (![]() ). Así, en cada paso se va agregando un descriptor al
modelo, y la desviación estándar es menor.
). Así, en cada paso se va agregando un descriptor al
modelo, y la desviación estándar es menor.
El número de regresiones que realiza SI es:
![]()
.
�Método de Reemplazo (RM)
El Método de Reemplazo es producto de la Tesis de doctorado del Dr. P.R. Duchowicz[15]. Consiste en una ``receta'' de fácil aplicación que, en la mayoría de los casos, produce resultados que coinciden con los de la búsqueda exacta o son muy cercanos. El funcionamiento del mismo es como sigue:
�Primero se fija el número de descriptores que
poseerá el modelo (![]() ). Luego se elige un conjunto inicial de descriptores
(
). Luego se elige un conjunto inicial de descriptores
(![]() ) y se realiza la regresión lineal. La elección del
conjunto inicial puede ser al azar o empleando algún otro método (como SI, por
ejemplo). A continuación, se toma uno de los descriptores del conjunto inicial,
y se lo reemplaza por todos los descriptores calculados (a excepción sí mismo).
Notemos que hay
) y se realiza la regresión lineal. La elección del
conjunto inicial puede ser al azar o empleando algún otro método (como SI, por
ejemplo). A continuación, se toma uno de los descriptores del conjunto inicial,
y se lo reemplaza por todos los descriptores calculados (a excepción sí mismo).
Notemos que hay ![]() �opciones para
este primer paso. De todos los conjuntos que se obtienen, se conserva el de
menor desviación estándar. Luego se elige la variable en el modelo resultante
que posea la mayor desviación en su coeficiente y se la reemplaza por todos los
descriptores (excepto ella misma), reteniendo nuevamente el conjunto resultante
con menor desviación estándar. Este procedimiento se repite con todos los
descriptores omitiendo los que ya fueron reemplazados.
�opciones para
este primer paso. De todos los conjuntos que se obtienen, se conserva el de
menor desviación estándar. Luego se elige la variable en el modelo resultante
que posea la mayor desviación en su coeficiente y se la reemplaza por todos los
descriptores (excepto ella misma), reteniendo nuevamente el conjunto resultante
con menor desviación estándar. Este procedimiento se repite con todos los
descriptores omitiendo los que ya fueron reemplazados.
�Una vez que todos los descriptores del modelo fueron reemplazados, se comienza nuevamente con la variable que posee la mayor desviación; este procedimiento se repite hasta que el conjunto de descriptores resulte invariante.
�Se procede de la misma manera para todos los
caminos posibles (![]() �caminos
restantes), y se elige el conjunto de variables que posea mayor poder
predictivo (menor desviación estándar del conjunto de validación).
�caminos
restantes), y se elige el conjunto de variables que posea mayor poder
predictivo (menor desviación estándar del conjunto de validación).
El número de regresiones que realiza una corrida de RM depende del conjunto de datos, ya que no es posible determinar a priori cuantos reemplazos será necesario realizar.
1.5 �Introducción al problema conformacional
En la sección 1.3 mencionamos que los descriptores 3D tienen en cuenta aspectos conformacionales de la estructura molecular; esto implica que su valor depende de las posiciones de los núcleos atómicos en el espacio, las cuales son optimizadas mediante cálculos.
�Es sabido que para moléculas medianamente grandes existen varias conformaciones de equilibrio[17,18] (i. e., las posiciones nucleares se encuentran en un mínimo de la hipersuperficie de potencial); si se calcula el valor de algún descriptor 3D para todas las conformaciones, cada una de ellas presentará un valor distinto. Es decir, los descriptores que se incluyen en el modelo dependen de qué confórmeros se eligen para representar a las moléculas que forman parte del estudio.
�Si disponemos de varios confórmeros por
molécula, la matriz ![]() �adquiere un
nuevo índice; es decir, sus elementos son ahora los
�adquiere un
nuevo índice; es decir, sus elementos son ahora los ![]() , los cuales representan al valor del descriptor
, los cuales representan al valor del descriptor ![]() �calculado para
el confórmero
�calculado para
el confórmero ![]() �de la molécula
�de la molécula ![]() . Para distinguir a la matriz de varios confórmeros de
aquella que contiene un confórmero por molécula, a la primera le agregamos una
tilde;
. Para distinguir a la matriz de varios confórmeros de
aquella que contiene un confórmero por molécula, a la primera le agregamos una
tilde; ![]() , y la definimos de la siguiente manera:
, y la definimos de la siguiente manera:
 (1.13)
(1.13)
�Donde ![]() �representa el
número de descriptores del conjunto,
�representa el
número de descriptores del conjunto, ![]() �el número de
moléculas y
�el número de
moléculas y ![]() �el número de
confórmeros por molécula. El problema conformacional se reduce a obtener, a
partir de la matriz english
�el número de
confórmeros por molécula. El problema conformacional se reduce a obtener, a
partir de la matriz english![]() �(de dimensión
�(de dimensión ![]() ), una matriz
), una matriz ![]() �(de dimensión
�(de dimensión ![]() ). A partir de las matrices
). A partir de las matrices ![]() , se pueden definir los vectores
, se pueden definir los vectores ![]() , los cuales contienen el descriptor
, los cuales contienen el descriptor ![]() �calculado para
todos los confórmeros de la molécula
�calculado para
todos los confórmeros de la molécula ![]() .
.
 (1.14)
(1.14)
Otras matrices
importantes en el problema conformacional son ![]() �y
�y ![]() . La primera de ellas contiene el valor de la
propiedad estudiada calculado para todos los confórmeros. La segunda contiene
el valor de la energía de todos los confórmeros. La dimensión de ambas matrices
es de
. La primera de ellas contiene el valor de la
propiedad estudiada calculado para todos los confórmeros. La segunda contiene
el valor de la energía de todos los confórmeros. La dimensión de ambas matrices
es de ![]() . Los elementos
. Los elementos ![]() �y
�y ![]() �representan al
valor de la propiedad predicho y a la energía del confórmero
�representan al
valor de la propiedad predicho y a la energía del confórmero ![]() �de la molécula
�de la molécula ![]() �respectivamente.
�respectivamente.
Una manera simple de solucionar el problema conformacional es tomar, de todos los confórmeros, aquel de menor energía. Este concepto y otros más los discutiremos más adelante. Otra manera de solucionarlo es directamente modelar a las moléculas en presencia del receptor (en los denominados "métodos dependientes de alineamiento") o en ausencia del mismo, como discutimos en la sección 1.1.1.
El objetivo general de este trabajo es considerar la flexibilidad conformacional molecular en los estudios QSAR; es decir, encontrar una solución al problema conformacional sin perder la información que se puede obtener de los distintos confórmeros disponibles. Para ello, nos centraremos en los métodos independientes de alineamiento, ya que son conceptualmente más simples y no es necesario conocer la estructura del receptor (lo cual a veces puede resultar una gran ventaja).
�Los objetivos específicos son:
�� Desarrollar algoritmos que permitan manipular los descriptores calculados para todos los confórmeros en lugar de uno solo por molécula.
�� Desarrollar metodologías nuevas que busquen:
(a)� Encontrar el confórmero más representativo del conjunto para cada molécula.
(b)� Considerar más de un confórmero por molécula.
�� Construir varios conjuntos moleculares y aplicar las metodologías desarrolladas sobre los mismos; luego comparar los resultados con los que se obtienen mediante el Método de Reemplazo usando la solución de mínima energía.
2 �Etapa inicial del estudio QSAR conformacional
2.1 �Preparación de los conjuntos moleculares
La preparación de los conjuntos moleculares para cualquier estudio QSAR requiere por lo general de dos pasos. El primero de ellos es necesario en cualquier método QSAR, y consiste en la representación de la estructura molecular de los compuestos pertenecientes al conjunto en estudio. El segundo consiste en optimizar la estructura molecular mediante cálculos; este paso solo es necesario si se desean utilizar descriptores 3D.
2.1.1 �Representación de las estructuras moleculares
La representación de las estructuras moleculares consiste en ``dibujar'' (o indicarle a la computadora por cualquier otro medio) las distintas moléculas que conforman el conjunto que se desea estudiar y cómo están formados los enlaces dentro de cada una de ellas. El resultado de la representación es un conjunto de archivos; cada uno de ellos contiene la información de los tipos de átomos, posiciones atómicas, multiplicidad y carga moleculares.
�Para representar las estructuras moleculares de todos los compuestos pertenecientes a los conjuntos que se estudiaron en este Trabajo de Tesina, se empleó HyperChem for Windows v6.0[19]. Se trata de un programa de modelado molecular muy reconocido, que permite obtener modelos moleculares fácilmente usando una interfaz gráfica. Cuenta con un paquete que permite estimar la distribución tridimensional de los átomos en el espacio sin necesidad de realizar cálculos. Si bien la aproximación que hace es pobre, el resultado es útil como punto de partida para realizar optimizaciones moleculares.
2.1.2 �Generación de confórmeros
Para los estudios que se realizaron en este trabajo, fue necesario generar varios confórmeros estables por cada molécula. Para realizar esta tarea, se empleó el paquete de Dinámica Molecular del HyperChem.
La dinámica molecular es un método que calcula las posiciones y velocidades futuras de los átomos a partir de las posiciones y velocidades actuales[20,21]. Para estudiar la evolución de un sistema, uno debe indicar las posiciones iniciales de los átomos y la temperatura; esta segunda variable sirve para conocer la energía de los átomos. Temperaturas más altas implican energías más altas, con lo cual todas las conormaciones de la molécula son accesibles ya que adquieren similar peso estadístico. La simulación determina primero la fuerza sobre cada átomo en función del tiempo; esta misma está definida como el gradiente del potencial. Dicho potencial o campo de fuerza se puede elegir de acuerdo a las necesidades del usuario. La dinámica se divide en tres pasos: calentamiento, estabilización y la simulación.
En la etapa de calentamiento, se lleva al sistema a la temperatura deseada. Luego, en la etapa de estabilización, se deja que el sistema evolucione para poder realizar el muestreo en condiciones de equilibrio. Por último, en la etapa de simulación, se deja que el sistema evolucione acorde con la resolución de las ecuaciones de Newton, mientras se hace un muestreo periódico de la estructura molecular, de manera tal que a lo largo de la simulación se van obteniendo varios confórmeros.
Los parámetros usados para la simulación en este Trabajo fueron:�
� Campo de fuerza: Mecánica Molecular (MM+)
� Calentamiento y estabilización:
- Tiempo de calentamiento: 0,1 ps (0,001 ps por paso)
- Temperatura inicial: 0 K
- Temperatura final: 900 K (30 K por paso)
- Tiempo de estabilización: 5 ps
- Tiempo de relajación: 0,5 ps
� Simulación:
- Tiempo de simulación: 10 ps
- Temperatura: 900 K
- Tiempo de relajación: 0,5 ps
- Número de simulaciones: 50
�Estas condiciones permitieron generar 50 confórmeros por molécula. Si se hubiese usado una temperatura menor, habría sido más probable que las moléculas se quedaran estancadas en mínimos locales de la hipersuperficie de potencial, por lo cual se habria
2.1.3 Optimización de la estructura de los confórmeros
Si bien la dinámica molecular implica simular la evolución del sistema químico a lo largo del tiempo, esto no significa que las estructuras obtenidas sean estables (es decir, que se encuentren en un mínimo de la hipersuperficie de energía potencial). Por lo tanto, es necesario recurrir a métodos cuánticos para garantizar la estabilidad de los confórmeros generados.
Para realizar la optimización estructural, recurrimos al método PM3. El mismo consiste en realizar cálculos tipo Hartree-Fock, pero parametrizando los valores de la mayoría de las integrales que se requieren para el cálculo variacional. Esta técnica reduce enormemente el costo computacional y sus resultados pueden considerarse aceptables para muchas optimizaciones de geometría[20].
Parámetros empleados:
� Hartree-Fock Restricto
� Convergencia SCF: 0,01 ![]()
� Algoritmo de optimización: Polak-Ribiere
2.2 Cálculo de los descriptores
Para calcular los descriptores, empleamos el programa en línea de acceso libre E-DRAGON[8], que permite calcular más de 1500 descriptores de diversos tipos: desde tipos de átomos (0D) y grupos funcionales (1D) hasta índices topológicos (2D) y geométricos (3D). El E-DRAGON no puede leer archivos provenientes de HyperChem (.hin), por lo cual se usó Open Babel[22] para convertirlos a un formato compatible (.sdf). En este Trabajo de Tesina solo se emplearon descriptores 3D, ya que son los únicos que varían de un confórmero a otro.
Para automatizar el cálculo de los descriptores se empleó el programa XMacro[23]. El mismo funciona bajo línea de comandos, los cuales fueron escritos mediante GNU BASH v4.1.5[24].
2.3 Conjuntos moleculares ensayados
Con el objeto de estudiar el comportamiento de nuestros algoritmos, se construyeron 13 conjuntos moleculares.
Los cuatro conjuntos iniciales son HLE, CatG, PR3 y Angio; los mismos están compuestos por las moléculas que se indican en las secciones 2.3.1 y 2.3.2. A partir de ellos se generaron cuatro conjuntos más mediante el intercambio de moléculas entre los conjuntos de calibración y validación; estos son HLE2, CatG2, PR3-2 y Angio2. Además de esto, se generaron otros cuatro conjuntos idénticos a HLE, CatG, PR3 y Angio pero usando los 20 primeros confórmeros que se generan durante la simulación de dinámica molecular en lugar de 50; estos conjuntos son: HLE(20), CatG(20), PR3(20) y Angio(20). Por último, se creó un conjunto más pequeño a partir de CatG para realizar la búsqueda exacta conformacional; el mismo se llama conjunto reducido (CR) y cuenta con 10 moléculas y 3 confórmeros por molécula.
El tamaño de los
distintos conjuntos empleados y otras propiedades de los mismos se resumen en
la tabla 2.3.1.
|
Conjunto |
|
|
|
|
|
A partir de |
|
CR |
10 |
3 |
10 |
0 |
20 |
CatG |
|
HLE |
132 |
50 |
90 |
42 |
692 |
[?] |
|
HLE2 |
132 |
50 |
74 |
58 |
692 |
HLE |
|
HLE(20) |
132 |
20 |
90 |
42 |
692 |
HLE |
|
CatG |
120 |
50 |
84 |
36 |
692 |
[?] |
|
CatG2 |
120 |
50 |
70 |
50 |
692 |
CatG |
|
CatG(20) |
120 |
20 |
84 |
36 |
692 |
CatG |
|
PR3 |
100 |
50 |
70 |
30 |
692 |
[?] |
|
PR3-2 |
100 |
50 |
53 |
47 |
692 |
PR3 |
|
PR3(20) |
100 |
20 |
70 |
30 |
692 |
PR3 |
|
Angio |
72 |
50 |
51 |
21 |
688 |
[?] |
|
Angio2 |
72 |
50 |
40 |
32 |
688 |
Angio |
|
Angio(20) |
72 |
20 |
51 |
21 |
688 |
Angio |
Tabla 2.3.1: Resumen de las propiedades de los distintos conjuntos ensayados
2.3.1 Inhibidores de la Enzima Convertidora de Angiotensina (ECA)
La ECA es una enzima circulatoria que participa en el sistema renina-angiotensina; este sistema está involucrado en la regulación del volumen extracelular y la vasoconstricción arterial. Su inhibición resulta crucial a la hora de regular la hipertensión arterial, así como también para el tratamiento de diversas enfermedades del corazón [27].
Se empleó un total de 72
moléculas, las cuales ya habían sido estudiadas en otro caso[26]. Las mismas se
encuentran en la figura 2.3.1. La tabla 2.3.2 contiene los valores
experimentales del parámetro ![]() , el cual expresa el opuesto del logaritmo de la
concentración de inhibidor que es necesaria para inhibir la actividad enzimática
en un 50%.
, el cual expresa el opuesto del logaritmo de la
concentración de inhibidor que es necesaria para inhibir la actividad enzimática
en un 50%.
A partir de estos inhibidores se armaron los conjuntos Angio, Angio2 y Angio(20)
Como se puede observar en
la figura 2.3.1, las moléculas pertenencientes al conjunto Angio y sus
derivados presentan una gran diversidad estructural.
|
Molécula |
|
Molécula |
|
Molécula |
|
|
M01 |
�9,64 |
�M18* |
�8,05 |
�M35* |
�5,8 |
|
�M02* |
�9,22 |
�M19* |
�8 |
�M36* |
�5,62 |
|
�M03* |
�9 |
�M20* |
�7,92 |
�M37* |
�5,62 |
|
�M04 |
�8,96 |
�M21 |
�7,64 |
�M38* |
�5,55 |
|
�M05* |
�8,92 |
�M22* |
�7,42 |
�M39* |
�5,52 |
|
�M06 |
�8,92 |
�M23* |
�7,31 |
�M40 |
�5,31 |
|
�M07 |
�8,77 |
�M24 |
�7,3 |
�M41 |
�5,08 |
|
�M08 |
�8,55 |
�M25* |
�7,19 |
�M42* |
�4,96 |
|
�M09* |
�8,54 |
�M26* |
�7 |
�M43 |
�4,77 |
|
�M10* |
�8,54 |
�M27 |
�6,7 |
�M44* |
�4,66 |
|
�M11* |
�8,52 |
�M28* |
�6,37 |
�M45* |
�4,51 |
|
�M12* |
�8,52 |
�M29* |
�6,34 |
�M46 |
�4,41 |
|
�M13* |
�8,43 |
�M30* |
�6,19 |
�M47 |
�4,32 |
|
�M14 |
�8,4 |
�M31* |
�6,15 |
�M48 |
�4,28 |
|
�M15* |
�8,22 |
�M32 |
�6,15 |
�M49 |
�3,89 |
|
�M16* |
�8,15 |
�M33 |
�6,11 |
�M50* |
�3,72 |
|
�M17* |
�8,11 |
�M34 |
�6,07 |
�M51* |
�3,64 |
|
T01 |
�8,66 |
�T08 |
�7,46 |
�T15 |
�7,19 |
|
�T02 |
�8,59 |
�T09 |
�7,4 |
�T16 |
�6,36 |
|
�T03 |
�8,32 |
�T10 |
�7,39 |
�T17 |
�5,59 |
|
�T04 |
�8,28 |
�T11 |
�7,29 |
�T18 |
�4,72 |
|
�T05 |
�8,19 |
�T12 |
�7,28 |
�T19 |
�4,59 |
|
�T06 |
�7,92 |
�T13 |
�7,25 |
�T20 |
�4,48 |
|
�T07 |
�7,7 |
�T14 |
�7,2 |
�T21 |
�4,17 |
Tabla 2.3.2: Valor experimental de ![]() �de los
inhibidores de ECA. Las moléculas cuyo nombre comienza con M pertenecen al
conjunto de calibración de Angio, mientras que las que comienzan con T
pertenecen al conjunto de validación de Angio. Las moléculas que contienen *
pertenecen al conjunto de validación de Angio2.
�de los
inhibidores de ECA. Las moléculas cuyo nombre comienza con M pertenecen al
conjunto de calibración de Angio, mientras que las que comienzan con T
pertenecen al conjunto de validación de Angio. Las moléculas que contienen *
pertenecen al conjunto de validación de Angio2.

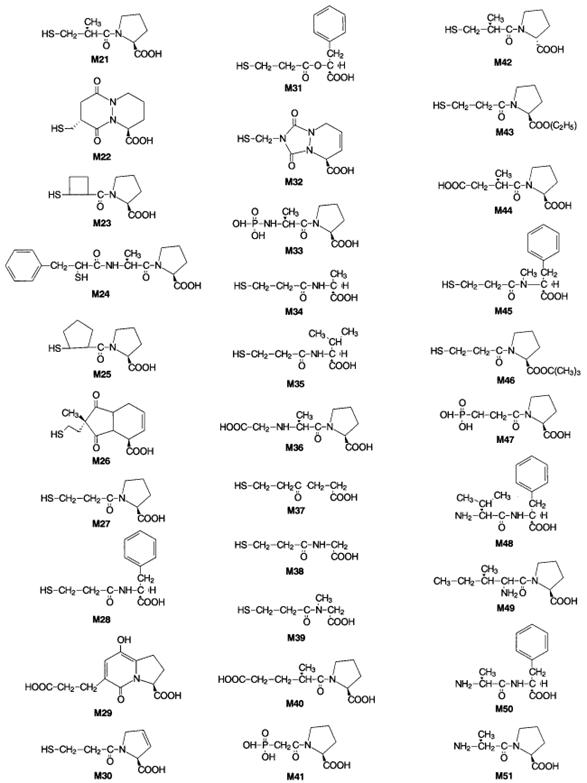

Figura 2.3.1: Inhibidores de ECA.
2.3.2 Inhibidores de enzimas basados en la 1,2,5-tiadiazolidina-3-ona-1,1-dióxido

[Esqueleto común a todas las moléculas]

[Esqueleto de las moléculas 97-113]
Figura 2.3.2: 1,2,5-tiadiazolidina-3-ona 1,1-dióxido
Las enzimas Leucocito Elastasa Humana (HLE), Proteinasa 3 (PR3) y Catepsina G (CatG) son esenciales en la inhibición de diversas enzimas que, si no son reguladas, participan de enfermedades como enfisema pulmonar, bronquitis, psoriasis y lesiones de isquemia-reperfusión[28,29,30,31].
En este Trabajo de
Tesina, se estudió la capacidad de 150 de ellas para actuar como inhibidores de
las enzimas Leucocito Elastasa Humana (HLE), Catepsina G (CatG) y Proteinasa-3
(PR3). En este caso, la variable que se estudió fue la constante de
inactivación de pseudosegundo orden ![]() [?]. Para ello, se tuvo en cuenta moléculas basadas en
la estructura de 1,2,5-tiadiazolidina-3-ona 1,1-dióxido (figura 2.3.2). Las
mismas se encuentran detalladas en la tabla de la página siguiente.
[?]. Para ello, se tuvo en cuenta moléculas basadas en
la estructura de 1,2,5-tiadiazolidina-3-ona 1,1-dióxido (figura 2.3.2). Las
mismas se encuentran detalladas en la tabla de la página siguiente.
|
Molécula |
|
|
�L |
|
�001 |
Isobutil |
�n-butil |
|
|
�002 |
Isobutil |
�(p- |
|
|
�003 |
Isobutil |
�(p-COOH)Bencil |
|
|
�004 |
Isobutil |
�(m-COOCH |
|
|
�005 |
Isobutil |
�(m-COOH)Bencil |
|
|
�006 |
Isobutil |
�(o-COOH |
|
|
�007 |
Isobutil |
�(o-COOH)Bencil |
|
|
�008 |
Isobutil |
�(p-CH |
|
|
�009 |
Isobutil |
�CH |
|
|
�010 |
Isobutil |
�CH |
|
|
�011 |
Isobutil |
�CH |
|
|
�012 |
Isobutil |
Metil |
|
|
�013 |
Isobutil |
Metil |
|
|
�014 |
Isobutil |
Bencil |
|
|
�015 |
Isobutil |
Metil |
|
|
�016 |
Isobutil |
Bencil |
|
|
�017 |
Isobutil |
|
|
|
�018 |
Isobutil |
Metil |
|
|
�019 |
Isobutil |
Metil |
|
|
�020 |
Isobutil |
Bencil |
|
|
�021 |
Isobutil |
Metil |
|
|
�022 |
Isobutil |
Bencil |
|
|
�023 |
Isobutil |
Metil |
|
|
�024 |
Isobutil |
Bencil |
|
|
�025 |
Benzil |
�H |
|
|
�026 |
Benzil |
Metil |
|
|
Molécula |
|
|
�L |
|
�027 |
Bencil |
Bencil |
|
|
�028 |
�(D) Bencil |
Bencil |
|
|
�029 |
Bencil |
�n-butil |
|
|
�030 |
Bencil |
�t-cinamil |
|
|
�031 |
Bencil |
|
|
|
�032 |
�(D) Bencil |
|
|
|
�033 |
Bencil |
�(p- |
|
|
�034 |
�n-propil |
Metil |
|
|
�035 |
�n-propil |
Bencil |
|
|
�036 |
|
Metil |
|
|
�037 |
|
Bencil |
|
|
�038 |
|
Bencil |
|
|
�039 |
�DL-etil |
Metil |
|
|
�040 |
�DL-etil |
Bencil |
|
|
�041 |
Isopropil |
Metil |
|
|
�042 |
Isopropil |
Bencil |
|
|
�043 |
�n-butil |
Metil |
|
|
�044 |
�n-butil |
Bencil |
|
|
�045 |
Bencil |
Bencil |
|
|
�046 |
Bencil |
Bencil |
|
|
�047 |
Bencil |
Bencil |
|
|
�048 |
Bencil |
Bencil |
|
|
�049 |
Bencil |
Bencil |
|
|
�050 |
Bencil |
Bencil |
|
|
�051 |
Bencil |
Bencil |
|
|
�052 |
Bencil |
Bencil |
|
|
Molécula |
|
|
�L |
|
�053 |
Bencil |
Bencil |
|
|
�054 |
Bencil |
Bencil |
|
|
�055 |
Bencil |
Bencil |
|
|
�056 |
Bencil |
Metil |
�2-benzoxazoliltio |
|
�057 |
Bencil |
Bencil |
�2-benzoxazoliltio |
|
�058 |
Bencil |
Bencil |
�6-amino-2-benzotiazoliltio |
|
�059 |
Bencil |
Bencil |
�5-fenil-1,3,4-oxadiazolil-2-tio |
|
�060 |
Isobutil |
Metil |
�3-fenil-5-mercapto-1,2,4-oxadiazolil |
|
�061 |
Isobutil |
Bencil |
�3-fenil-5-mercapto-1,2,4-oxadiazolil |
|
�062 |
Isobutil |
Metil |
�2-mercaptobenzothiazolil |
|
�063 |
Isobutil |
Bencil |
�2-mercaptobenzothiazolil |
|
�064 |
Isobutil |
Metil |
�2-mercaptobenzoxazolil |
|
�065 |
Isobutil |
Bencil |
�2-mercaptobenzoxazolil |
|
�066 |
Isobutil |
Metil |
�4,5-difenil-2-mercapto-oxazolil |
|
�067 |
Isobutil |
Bencil |
�4,5-difenil-2-mercapto-oxazolil |
|
�068 |
Isobutil |
Metil |
�5-fenil-2-mercapto-1,2,4-oxadiazolil |
|
�069 |
Isobutil |
Bencil |
�5-fenil-2-mercapto-1,2,4-oxadiazolil |
|
�070 |
Isobutil |
Metil |
�5-fenil-2-mercaptobenzoxazolil |
|
�071 |
Isobutil |
Bencil |
�5-fenil-2-mercaptobenzoxazolil |
|
�072 |
Bencil |
Metil |
�5-fenil-2-mercapto-1,3,4-oxadiazolil |
|
�073 |
Bencil |
Bencil |
�5-fenil-2-mercapto-1,3,4-oxadiazolil |
|
�074 |
Bencil |
Metil |
�2-mercaptobenzoxazolil |
|
�075 |
Bencil |
Bencil |
�2-mercaptobenzoxazolil |
|
�076 |
Bencil |
Bencil |
�6-amino-2-mercaptobenzoxazolil |
|
�077 |
�(S) Isobutil |
�H |
BocGly |
|
�078 |
�(S) Isobutil |
�H |
Gly (HCl) |
Boc: t-butil carbamato; Gly: glicina
|
Molécula |
|
|
�L |
|
�079 |
�(S) Isobutil |
Metil |
BocGly |
|
�080 |
�(S) Isobutil |
Metil |
Gly (HCl) |
|
�081 |
�(S) Isobutil |
�H |
Boc-L-Phe |
|
�082 |
�(S) Isobutil |
�H |
�L-Phe (HCl) |
|
�083 |
�(S) Isobutil |
Metil |
Boc-L-Phe |
|
�084 |
�(S) Isobutil |
Metil |
Boc-D-Phe |
|
�085 |
�(S) Isobutil |
Bencil |
Boc-L-Phe |
|
�086 |
�(S) Isobutil |
Bencil |
Boc-D-Phe |
|
�087 |
�(S) Isobutil |
Metil |
Cbz-L-Phe |
|
�088 |
�(S) Isobutil |
Metil |
Cbz-D-Phe |
|
�089 |
�(S) Isobutil |
Metil |
�L-Phe (HCl) |
|
�090 |
�(S) Isobutil |
Metil |
�D-Phe (HCl) |
|
�091 |
�(S) Isobutil |
Metil |
Boc-L-Met |
|
�092 |
�(S) Isobutil |
Metil |
�L-Met (HCl) |
|
�093 |
�(S) Isobutil |
Metil |
Boc-L- |
|
�094 |
Bencil |
Bencil |
Boc-L-Phe |
|
�095 |
Bencil |
Bencil |
�L-Phe (HCl) |
|
�096 |
Bencil |
Bencil |
Boc-D-Phe |
Phe: fenilalanina; Cbz: Bencilcarbamato; Met: metionina
|
Molécula |
|
|
|
|
|
�097 |
Isobutil |
Metil |
Isobutiloxi |
Metil |
|
�098 |
Isobutil |
Metil |
�n-butiloxi |
Metil |
|
�099 |
Isobutil |
Metil |
benciloxi |
Metil |
|
�100 |
Isobutil |
Metil |
Metoxi |
Fenil |
|
�101 |
Isobutil |
Metil |
�n-butiloxi |
Fenil |
|
�102 |
Isobutil |
Bencil |
Fenil |
Metil |
|
�103 |
Isobutil |
Metil |
Benciloxi |
Metil |
|
�104 |
Isobutil |
Metil |
Metil |
�(p- |
|
�105 |
Isobutil |
Metil |
|
Metil |
|
�106 |
Isobutil |
Bencil |
|
Metil |
|
�107 |
Isobutil |
Metil |
|
Metil |
|
�108 |
Isobutil |
Bencil |
|
Metil |
|
�109 |
Isobutil |
Metil |
|
Fenil |
|
�110 |
Isobutil |
Bencil |
|
Metil |
|
�111 |
Bencil |
Bencil |
Metoxi |
Fenil |
|
�112 |
Bencil |
Bencil |
�n-butiloxi |
Fenil |
|
�113 |
Bencil |
Bencil |
�n-butiloxi |
Metil |
|
Molécula |
|
|
�L |
|
�114 |
Etil* |
�H |
|
|
�115 |
Etil* |
Metil |
|
|
�116 |
Etil* |
Bencil |
|
|
�117 |
Etil* |
�H |
�2,6-Diclorobenzoato |
|
�118 |
�n-Propil |
�H |
|
|
�119 |
�n-Propil |
�(p- |
|
|
�120 |
Isopropil |
�H |
|
|
�121 |
Isobutil |
�H |
|
|
�122 |
Isobutil |
Metil |
|
|
�123 |
Isobutil |
Bencil |
|
|
�124 |
Isobutil |
�(p- |
|
|
�125 |
Isobutil |
Bencil |
|
|
�126 |
Isobutil |
�H |
Benzoato |
|
�127 |
Isobutil |
Metil |
Benzoato |
|
�128 |
Isobutil |
Bencil |
Benzoato |
|
�129 |
Isobutil |
�H |
�2,6-Diclorobenzoato |
|
�130 |
Isobutil |
Metil |
�2,6-Diclorobenzoato |
|
�131 |
Isobutil |
Bencil |
�2,6-Diclorobenzoato |
|
�132 |
Isobutil |
�( |
�2,6-Diclorobenzoato |
|
�133 |
Isobutil |
�H |
�trans-Cinamato |
|
�134 |
Isobutil |
Metil |
�trans-Cinamato |
|
�135 |
Isobutil |
�H |
�(alfa)-Flourocinamato |
|
�136 |
Isobutil |
Metil |
�(alfa)-Flourocinamato |
|
�137 |
Isobutil |
Metil |
Dihidrocinamato |
|
�138 |
Isobutil |
Bencil |
Dihidrocinamato |
|
�139 |
Isobutil |
Metil |
Fenilacetato |
|
Molécula |
|
|
�L |
|
�139 |
Isobutil |
Metil |
Fenilacetato |
|
�140 |
Isobutil |
Bencil |
Fenilacetato |
|
�141 |
Isobutil |
Metil |
�3-Nicotinato |
|
�142 |
Isobutil |
Metil |
Feniltioacetato |
|
�143 |
Isobutil |
Metil |
Fenilsulfonilacetato |
|
�144 |
Isobutil |
Metil |
�(4-Piridiltio) acetato |
|
�145 |
Isobutil |
Metil |
�4-(N-Metil-4-piridil) acetato |
|
�146 |
Isobutil |
Metil |
�(S) Mandelato |
|
�147 |
Isobutil |
Metil |
|
|
�148 |
Isobutil |
Metil |
|
|
�149 |
Bencil |
Bencil |
�2,6-Diclorobenzoato |
|
�150 |
Bencil |
Bencil |
|
|
Molécula |
|
Molécula |
|
Molécula |
|
|
001** |
�8230 |
�060** |
�153460 |
�104 |
�9900 |
|
�002** |
�67800 |
�061* |
�67840 |
�105 |
�140500 |
|
�003 |
�7800 |
�062* |
�67300 |
�106** |
�148900 |
|
�004** |
�63600 |
�063* |
�22360 |
�107 |
�229400 |
|
�005** |
�38700 |
�064** |
�80580 |
�108* |
�134000 |
|
�006** |
�25800 |
�065** |
�174440 |
�109** |
�92700 |
|
�007* |
�7690 |
�066** |
�1540 |
�110 |
�14100 |
|
�008* |
�26700 |
�067* |
�560 |
�113** |
�1970 |
|
�009* |
�2020 |
�068* |
�25280 |
�114* |
�300 |
|
�010* |
�1710 |
�069* |
�168130 |
�115** |
�400 |
|
�011** |
�1050 |
�070 |
�22630 |
�116* |
�1500 |
|
�012 |
�4590 |
�071** |
inactivo |
�117 |
�3700 |
|
�013** |
�32200 |
�072* |
inactivo |
�118 |
�1300 |
|
�014** |
�219000 |
�073** |
inactivo |
�119 |
�4500 |
|
�015 |
�9490 |
�074* |
inactivo |
�120** |
inactivo |
|
�016 |
�95200 |
�075** |
inactivo |
�121** |
�4100 |
|
�017* |
�6590 |
�076* |
inactivo |
�122 |
�42700 |
|
�018** |
�22300 |
�077** |
�62600 |
�123* |
�60500 |
|
�019* |
�47500 |
�078 |
�5000 |
�124 |
�13700 |
|
�020 |
�165000 |
�079** |
�117000 |
�125* |
�163300 |
|
�021 |
�15400 |
�080** |
�16900 |
�126 |
�91600 |
|
�022* |
�9990 |
�081 |
�70100 |
�127* |
�267500 |
|
�023 |
�38200 |
�082 |
�49500 |
�128** |
�335900 |
|
�024** |
�240000 |
�083** |
�358100 |
�129* |
�711800 |
|
�025** |
inactivo |
�084* |
�613200 |
�130** |
�4928300 |
|
�026** |
inactivo |
�085** |
�652400 |
�131 |
�2381000 |
Tabla2.3.4: Valor experimental de ![]() �de los
inhibidores de HLE. El * indica que dicha molécula pertenece al conjunto de
validación de HLE y HLE(20) mientras que ** indica pertenencia al conjunto de
validación de HLE2.
�de los
inhibidores de HLE. El * indica que dicha molécula pertenece al conjunto de
validación de HLE y HLE(20) mientras que ** indica pertenencia al conjunto de
validación de HLE2.
|
Molécula |
|
Molécula |
|
Molécula |
|
|
027** |
inactivo |
�086** |
�752500 |
�132** |
�1220000 |
|
�028* |
inactivo |
�087* |
�637900 |
�133** |
�31300 |
|
�029** |
inactivo |
�088** |
�1056800 |
�134** |
�318200 |
|
�030* |
inactivo |
�089* |
�95000 |
�135** |
�56400 |
|
�031** |
inactivo |
�090 |
�187700 |
�136 |
�628200 |
|
�032 |
inactivo |
�091* |
�304400 |
�137 |
�296300 |
|
�033** |
inactivo |
�092** |
�69800 |
�138** |
�3200 |
|
�034 |
�780 |
�093* |
�157500 |
�139* |
�357100 |
|
�035 |
�7260 |
�094** |
inactivo |
�140 |
�63800 |
|
�036* |
inactivo |
�095** |
inactivo |
�141** |
�105100 |
|
�037** |
inactivo |
�096** |
inactivo |
�142 |
�395400 |
|
�038* |
inactivo |
�097** |
�11900 |
�143* |
�753200 |
|
�039** |
�190 |
�098* |
�40500 |
�144 |
�161300 |
|
�040* |
�810 |
�099* |
�22000 |
�145** |
�108300 |
|
�041** |
inactivo |
�100** |
�51100 |
�146** |
�308100 |
|
�042** |
inactivo |
�101 |
�70500 |
�147** |
�71100 |
|
�043** |
�1080 |
�102* |
�71000 |
�148* |
�79700 |
|
�044* |
�8060 |
�103** |
�28300 |
�149* |
�3600 |
|
Molécula |
|
Molécula |
|
Molécula |
|
|
001** |
�430 |
�044** |
inactivo |
�102* |
�16000 |
|
�002 |
�1280 |
�060* |
�16350 |
�103** |
�10100 |
|
�003** |
�840 |
�061** |
�1510 |
�104 |
�3200 |
|
�004** |
�7080 |
�062** |
�5990 |
�105 |
�27500 |
|
�005* |
�10300 |
�063* |
�1070 |
�106** |
�2400 |
|
�006** |
�2440 |
�064 |
�10350 |
�107 |
�27400 |
|
�007 |
�1050 |
�065** |
�9130 |
�108** |
�30100 |
|
�008** |
�1770 |
�066 |
�1560 |
�109** |
�29200 |
|
�009* |
�1830 |
�067** |
�340 |
�110* |
�5200 |
|
�011 |
�310 |
�068* |
�12630 |
�111** |
inactivo |
|
�012* |
�370 |
�069* |
�3590 |
�112** |
inactivo |
|
�013 |
�6280 |
�070* |
�11100 |
�113 |
inactivo |
|
�014** |
�16200 |
�071** |
�1090 |
�114 |
�900 |
|
�015 |
�2250 |
�072** |
inactivo |
�115** |
�300 |
|
�016** |
�5240 |
�073 |
inactivo |
�116 |
�400 |
|
�018** |
�9580 |
�074** |
inactivo |
�117 |
�3400 |
|
�019** |
�16900 |
�075** |
inactivo |
�118 |
�5100 |
|
�020** |
�20300 |
�076* |
inactivo |
�119** |
�2000 |
|
�021* |
�8020 |
�077* |
�1700 |
�120* |
inactivo |
|
�022* |
�3250 |
�079* |
�28000 |
�121 |
�2400 |
|
�023** |
�4780 |
�081* |
�1800 |
�122** |
�5900 |
|
�024* |
�2250 |
�083* |
�64600 |
�123** |
�1800 |
|
�027** |
inactivo |
�085** |
�11900 |
�126** |
�2600 |
|
�033* |
inactivo |
�087** |
�126200 |
�127 |
�12800 |
|
�034** |
�1830 |
�088* |
�157300 |
�128 |
�26000 |
Tabla2.3.5: Valor experimental de ![]() �de los
inhibidores de PR3. * indica que dicha molécula pertenece al conjunto de
validación de PR3 y PR3(20) mientras que ** indica pertenencia al conjunto de
validación de PR3-2.
�de los
inhibidores de PR3. * indica que dicha molécula pertenece al conjunto de
validación de PR3 y PR3(20) mientras que ** indica pertenencia al conjunto de
validación de PR3-2.
|
Molécula |
|
�Molécula |
|
�Molécula |
|
|
035* |
�4960 |
�090 |
�13500 |
�129 |
�88200 |
|
�036 |
inactivo |
�094* |
�330 |
�130** |
�33400 |
|
�037** |
inactivo |
�095** |
�2320 |
�131 |
�14400 |
|
�038** |
inactivo |
�096** |
�240 |
�132** |
�196400 |
|
�039* |
�200 |
�097* |
�1200 |
�133** |
�9500 |
|
�040** |
�80 |
�098** |
�3400 |
�134* |
�9700 |
|
�041* |
inactivo |
�099* |
�3000 |
�149** |
�3500 |
|
�042** |
inactivo |
�100* |
�6100 |
|
|
|
�043* |
inactivo |
�101** |
�6400 |
|
|
|
Molécula |
|
Molécula |
|
Molécula |
|
|
001** |
inactivo |
�041* |
inactivo |
�090 |
�40 |
|
�002** |
�790 |
�042 |
inactivo |
�091** |
inactivo |
|
�003** |
�70 |
�043** |
inactivo |
�092 |
�10 |
|
�004* |
�80 |
�044** |
�610 |
�093* |
�60 |
|
�005** |
�350 |
�045 |
�10600 |
�103 |
�200 |
|
�006** |
�60 |
�046* |
�22700 |
�107 |
�60 |
|
�007* |
�150 |
�047* |
�12800 |
�108** |
�70 |
|
�008** |
�290 |
�048** |
�12680 |
�109** |
inactivo |
|
�009** |
�30 |
�049* |
�12330 |
�110** |
�70 |
|
�010* |
inactivo |
�050* |
�8500 |
�111 |
�90 |
|
�011** |
inactivo |
�051* |
�25230 |
�112 |
�80 |
|
�012 |
inactivo |
�052** |
�17370 |
�113** |
�5400 |
|
�013** |
inactivo |
�053** |
�350 |
�114* |
inactivo |
|
�014 |
�180 |
�054 |
�20710 |
�115 |
inactivo |
|
�015* |
inactivo |
�055 |
�66680 |
�116** |
inactivo |
|
�016 |
�110 |
�056* |
�430 |
�117 |
inactivo |
|
�017 |
inactivo |
�057** |
�17130 |
�118* |
inactivo |
|
�018** |
�100 |
�058 |
�15740 |
�119** |
�200 |
|
�019* |
�160 |
�059** |
�490 |
�120 |
inactivo |
|
�020* |
�70 |
�064* |
�30 |
�121* |
�70 |
|
�021 |
�20 |
�065 |
�60 |
�122** |
inactivo |
|
�022* |
�60 |
�071* |
�50 |
�123* |
�200 |
|
�023 |
inactivo |
�072 |
�490 |
�124** |
�300 |
|
�024 |
inactivo |
�073* |
�17460 |
�126** |
�1100 |
|
�025** |
�30 |
�074** |
�430 |
�127 |
�300 |
|
�026 |
�120 |
�075* |
�17130 |
�128** |
�90 |
Tabla 2.3.6: Valor experimental de ![]() �de los
inhibidores de CatG. * indica que dicha molécula pertenece al conjunto de
validación de CatG y CatG(20) mientras que ** indica pertenencia al conjunto de
validación de CatG2. Las
moléculas subrayadas pertenecen al conjunto CR.
�de los
inhibidores de CatG. * indica que dicha molécula pertenece al conjunto de
validación de CatG y CatG(20) mientras que ** indica pertenencia al conjunto de
validación de CatG2. Las
moléculas subrayadas pertenecen al conjunto CR.
|
Molécula |
|
Molécula |
|
Molécula |
|
|
028 |
�1580 |
�077 |
�150 |
�130** |
�60 |
|
�029* |
�320 |
�078** |
�70 |
�131** |
�30 |
|
�030* |
�760 |
�079** |
�60 |
�132 |
�2300 |
|
�031 |
�1130 |
�080* |
�20 |
�133* |
�1200 |
|
�032* |
�280 |
�081** |
inactivo |
�134** |
�100 |
|
�033** |
�3760 |
�082* |
�100 |
�136 |
�100 |
|
�034 |
inactivo |
�083* |
inactivo |
�139 |
�200 |
|
�035** |
�130 |
�084 |
�40 |
�141* |
�90 |
|
�036** |
inactivo |
�085** |
�400 |
�142** |
�70 |
|
�037* |
inactivo |
�086 |
�60 |
�145** |
inactivo |
|
�038** |
inactivo |
�087** |
�140 |
�146 |
�100 |
|
�039** |
inactivo |
�088** |
�50 |
�149* |
�2200 |
|
�040 |
inactivo |
�089 |
�50 |
�150** |
�10600 |
Para resolver el problema
conformacional (reducir la matriz ![]() �a otra matriz
�a otra matriz ![]() ), fue necesario desarrollar varios algoritmos. El
programa de cómputo empleado para tal fin fue MATLAB 7.7.0.471[33]; un
lenguaje de programación de alto nivel que permite realizar tareas
computacionalmente costosas de manera mucho más rápida que los lenguajes de
programación tradicionales como C, C++ y Fortran.
), fue necesario desarrollar varios algoritmos. El
programa de cómputo empleado para tal fin fue MATLAB 7.7.0.471[33]; un
lenguaje de programación de alto nivel que permite realizar tareas
computacionalmente costosas de manera mucho más rápida que los lenguajes de
programación tradicionales como C, C++ y Fortran.
Como se mencionó en la sección 1.6, se trabajó con dos tipos de algoritmos: aquellos que consideran un confórmero por molécula y aquellos que consideran a varios confórmeros. En este capítulo se describe el funcionamiento de todos los algoritmos que se desarrollaron en este trabajo.
3.1 Generalidades sobre los algoritmos desarrollados
Los algoritmos desarrollados en este trabajo siguen algunos lineamientos generales que resultará provechoso dar a conocer para que su funcionamiento sea más fácil de entender.
Con la palabra parámetro
nos referimos a un valor numérico que no está relacionado directamente con
la información de las moléculas sino con el funcionamiento del algoritmo. Por
ejemplo, el número de iteraciones a repetir en un cierto algoritmo, o al número
de descriptores que deseamos que tenga un modelo son parámetros. Por otro lado,
la palabra variable se refiere a todo número, vector o matriz que
contenga información sobre las moléculas; por ejemplo, las matrices ![]() �e
�e ![]() . Si una variable es una matriz o vector, nos
referiremos a cualquier elemento perteneciente a la misma con la palabra subvariable.
. Si una variable es una matriz o vector, nos
referiremos a cualquier elemento perteneciente a la misma con la palabra subvariable.
3.1.1 Criterios de selección de confórmeros
Muchos de los algoritmos que se desarrollaron requieren algún criterio de selección para determinar qué confórmero se usará. Dicho criterio implica comparar el contenido de dos variables o de dos o más subvariables, las cuales representan al valor de un descriptor calculado para un confórmero en particular de alguna molécula, el valor experimental de su propiedad, el predicho, etc. Un problema que se puede presentar es que dichas subvariables tengan el mismo valor, con lo cual el criterio no sirve para optar por un confórmero u otro.
Cuando esto ocurre, uno podría elegir entre los dos confórmeros al azar, pero proceder de esta manera brinda resultados irreproducibles en la mayoría de los casos. Por este motivo, se optó por comparar un descriptor que no se repita entre ninguno de los confórmeros y elegir aquel confórmero que tenga menor valor de dicho descriptor. Por ejemplo, si se quiere elegir a los confórmeros de mínima energía, y para la molécula 42 los confórmeros 23 y 35 poseen el mismo valor de energía (el mínimo), entonces se usará aquel confórmero cuyo valor del descriptor destinado a tal fin sea menor.
El índice que representa dicho descriptor es uno de los parámetros que es necesario especificar, como se indica en la sección 3.1.3.
3.1.2 Criterios para reportar los resultados
En la sección 1.4.2 destacamos la importancia de que los modelos obtenidos mediante los distintos algoritmos no sobreajusten al conjunto de calibración. Esto se debe a que si el ajuste solo es bueno en dicho conjunto, el modelo no tiene poder predictivo. Por otra parte, si el modelo generado sobreajusta al conjunto de validación, esto tampoco quiere decir que tenga buen poder predictivo, ya que si no es capaz de predecir bien el valor de la propiedad de las moléculas del conjunto de calibración, no hay manera de garantizar que el mismo modelo pueda predecir valores de propiedades/actividades en moléculas nuevas.
Cuando un algoritmo da
como resultado varios modelos, no es correcto elegir el que menor ![]() �tenga sin mirar
antes su
�tenga sin mirar
antes su ![]() , ya que corre el riesgo de que dicho modelo
sobreajuste al conjunto de validación; además, elegir un modelo mirando
exclusivamente si las predicciones son correctas es ``hacer trampa'', ya que
las mismas dejan de ser predicciones, y pasan a ser otro ajuste. Dicho en otras
palabras, el conjunto de validación pasa a ser un nuevo conjunto de
calibración.
, ya que corre el riesgo de que dicho modelo
sobreajuste al conjunto de validación; además, elegir un modelo mirando
exclusivamente si las predicciones son correctas es ``hacer trampa'', ya que
las mismas dejan de ser predicciones, y pasan a ser otro ajuste. Dicho en otras
palabras, el conjunto de validación pasa a ser un nuevo conjunto de
calibración.
Es necesario establecer
un criterio que tenga en cuenta estos problemas a la hora de reportar los
resultados; no todos los modelos obtenidos mediante un algoritmo son válidos.
El criterio establecido para este Trabajo de Tesina es el siguiente: de todos
los modelos obtenidos, se busca aquel cuyo ![]() �sea menor; a
dicho valor de
�sea menor; a
dicho valor de ![]() �lo llamamos
�lo llamamos ![]() . Luego se tienen en cuenta todos los modelos cuyo
. Luego se tienen en cuenta todos los modelos cuyo ![]() �no supere en un
porcentaje dado al valor de
�no supere en un
porcentaje dado al valor de ![]() .
.
De esta manera, un porcentaje bajo asegura que se está observando más al conjunto de calibración que al de validación.
3.1.3 Parámetros y variables empleados
Los algoritmos
desarrollados en este Trabajo de Tesina se valen de ciertos parámetros y
variables que deben ser especificados por el usuario. Además de ![]() ,
, ![]() ,
, ![]() �y
�y ![]() �(definidos en
las secciones 1.4.1 y 1.5), otros parámetros que es necesario especificar
son:
�(definidos en
las secciones 1.4.1 y 1.5), otros parámetros que es necesario especificar
son:
� ![]() : es un índice que indica qué descriptor que se usará
para elegir entre dos confórmeros cuando posean el mismo valor del criterio de
distinción de la sección 3.1.1.
: es un índice que indica qué descriptor que se usará
para elegir entre dos confórmeros cuando posean el mismo valor del criterio de
distinción de la sección 3.1.1.
� ![]() : es un índice que indica el porcentaje de
: es un índice que indica el porcentaje de ![]() �que se usará
para considerar los modelos, como se explicó en la sección 3.1.2.
�que se usará
para considerar los modelos, como se explicó en la sección 3.1.2.
� ![]() : es un vector que indica los índices de las moléculas
que se usarán en el conjunto de calibración.
: es un vector que indica los índices de las moléculas
que se usarán en el conjunto de calibración.
� ![]() : vector que indica los índices de las moléculas que
se usarán en el conjunto de validación.
: vector que indica los índices de las moléculas que
se usarán en el conjunto de validación.
3.2 Algoritmos que consideran el confórmero más representativo para cada molécula
3.2.1 Búsqueda exacta conformacional
La búsqueda exacta
conformacional consiste en realizar todas las regresiones posibles, teniendo en
cuenta todos los descriptores de ![]() �(en lugar de
usar
�(en lugar de
usar ![]() , como lo hace la búsqueda exacta tradicional de la
sección %d.1.4.2). Este método resulta extremadamente costoso, ya que a la
cantidad de regresiones dada por la ecuación (1.10) es necesario agregarle un
término que tenga en cuenta la cantidad de confórmeros. El número total de regresiones
que se realizan en una búsqueda exacta conformacional está dado por la
ecuación:
, como lo hace la búsqueda exacta tradicional de la
sección %d.1.4.2). Este método resulta extremadamente costoso, ya que a la
cantidad de regresiones dada por la ecuación (1.10) es necesario agregarle un
término que tenga en cuenta la cantidad de confórmeros. El número total de regresiones
que se realizan en una búsqueda exacta conformacional está dado por la
ecuación:
![]() (3.1)
(3.1)
Esto resulta en
cantidades monstruosas de regresiones aún para conjuntos muy pequeños. Por
ejemplo, usando un conjunto de 700 descriptores, 5 confórmeros por molécula y
10 moléculas, para obtener un modelo de 4 descriptores es necesario realizar ![]() �regresiones,
las cuales tardarían aproximadamente
�regresiones,
las cuales tardarían aproximadamente ![]() �años en ser
llevadas a cabo.
�años en ser
llevadas a cabo.
De cualquier manera, como indicaremos en el capítulo 4, la búsqueda exacta conformacional sirvió para mostrar que el conjunto de mínima energía no es siempre el que mejor representa a la propiedad en estudio.
3.2.2 Inclusión de a pasos Conformacional (CS)
SI Conformacional es un método iterativo. La idea del mismo consiste en que en cada iteración se genera un modelo; dicho modelo se usa para predecir el valor de la propiedad de todos los confórmeros y, a partir de dicho valor, se emplea algún criterio para escoger uno de entre todos ellos. Luego se usa ese conjunto de confórmeros en la siguiente iteración. Al final del proceso, se dispone de varios conjuntos de confórmeros, y se elige aquel que sea más representativo.
El funcionamiento de CS
depende de varios parámetros y variables, especificados por el usuario. Los
mismos son: ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() .
.
Todos estos parámetros y
variables fueron definidos en secciones anteriores, a excepción de ![]() : número de iteraciones a realizar con cada criterio.
: número de iteraciones a realizar con cada criterio.
De manera detallada, CS funciona como sigue:
1.�
Dada la matriz ![]() , se utiliza algún criterio para obtener una matriz
, se utiliza algún criterio para obtener una matriz ![]() ; en nuestro caso, empleamos la matriz correspondiente
a los confórmeros de menor energía.
; en nuestro caso, empleamos la matriz correspondiente
a los confórmeros de menor energía.
2.�
En el primer paso del método, ![]() . Se emplea el método de inclusión de a pasos (sección
%d.1.4.2) para crear un modelo de
. Se emplea el método de inclusión de a pasos (sección
%d.1.4.2) para crear un modelo de ![]() �descriptores.
�descriptores. ![]() . El superíndice
. El superíndice ![]() �indica que los
vectores
�indica que los
vectores ![]() �provienen de la
matriz
�provienen de la
matriz ![]() .
.
3.�
Utiliza dicho modelo para obtener ![]() .
.
4.�
Para cada ![]() , compara los elementos
, compara los elementos ![]() �y utiliza un
criterio para asignar el cofórmero representativo
�y utiliza un
criterio para asignar el cofórmero representativo ![]() �de cada
molécula
�de cada
molécula ![]() .
.
5.�
En el siguiente paso, (![]() ) se construye la nueva matriz
) se construye la nueva matriz ![]() �a partir de
�a partir de ![]() �y los
confórmeros hallados en el paso anterior; luego se repite el procedimiento a
partir de 2.
�y los
confórmeros hallados en el paso anterior; luego se repite el procedimiento a
partir de 2.
�Los pasos 2. a 6. se repiten tantas veces como
lo indique ![]() . Como mencionamos anteriormente, el algoritmo solo
reportará los resultados producidos según el criterio
. Como mencionamos anteriormente, el algoritmo solo
reportará los resultados producidos según el criterio ![]() .
.
El criterio empleado en el paso 4. puede ser cualquiera, con la condición de que no se usen valores experimentales. Esto se debe a que el método debe poder utilizarse para predecir valores de propiedad que no fueron medidos. Además, se pueden combinar varios criterios; es decir, realizar un número de iteraciones con un criterio, y luego con los otros.
Los criterios que empleamos en este trabajo fueron:
� Criterio 1: Para cada molécula, elige aquel confórmero cuyo valor de la propiedad predicha en el paso 3. sea menor.
� Criterio 2: El confórmero elegido es aquel cuyo valor de propiedad predicha se acerque más al promedio de todos los confórmeros.
� Criterio 3: Elige el confórmero cuyo valor de propiedad predicha sea mayor.
�En las pruebas realizadas, se combinó los tres criterios.
3.3 Algoritmos que consideran varios confórmeros para cada molécula (CRM)
Este tipo de métodos
definen cada elemento de matriz de ![]() �a partir de los
vectores
�a partir de los
vectores ![]() , definidos en la sección 1.5. En este Trabajo de
Tesina, se desarrollaron algoritmos que definen, a partir de la matriz
, definidos en la sección 1.5. En este Trabajo de
Tesina, se desarrollaron algoritmos que definen, a partir de la matriz ![]() �(de dimensiones
�(de dimensiones
![]() ), las siguientes matrices:
), las siguientes matrices:
� ![]() :
: ![]()
� ![]() :
: ![]()
� ![]() �:
�: ![]()
� ![]() �:
�: ![]()
� ![]() : matriz de los confórmeros de mínima energía
: matriz de los confórmeros de mínima energía
�La dimensión de todas las matrices obtenidas
es ![]() . Cada una de estas matrices contiene un confórmero
por molécula; sin embargo, la matriz
. Cada una de estas matrices contiene un confórmero
por molécula; sin embargo, la matriz ![]() �posee
información sobre todos los confórmeros, y la matriz
�posee
información sobre todos los confórmeros, y la matriz ![]() �posee
información sobre dos confórmeros, de manera que la matriz:
�posee
información sobre dos confórmeros, de manera que la matriz:
![]() (3.2)
(3.2)
posee información sobre todos los confórmeros.
Lo que resta es realizar
las regresiones necesarias para obtener modelos a partir de la información que
se dispone en la matriz ![]() . Como explicaremos en el capítulo 4, para tal fin se
empleó el método RM aplicado sobre distintas submatrices definidas a partir de
. Como explicaremos en el capítulo 4, para tal fin se
empleó el método RM aplicado sobre distintas submatrices definidas a partir de ![]() . Por este motivo, a este tipo de algoritmos se los
engloba bajo el nombre CRM (Método de Reemplazo Conformacional).
. Por este motivo, a este tipo de algoritmos se los
engloba bajo el nombre CRM (Método de Reemplazo Conformacional).
En este capítulo daremos a conocer los parámetros empleados y los resultados que se obtuvieron luego de aplicar los algoritmos a distintos conjuntos moleculares. Luego daremos una breve interpretación de los mismos. Finalmente expondremos las conclusiones de este trabajo.
En esta sección se
exponen todas las tareas realizadas a fin de probar los algoritmos
desarrollados en este trabajo. En todos los casos a excepción de SI, los algoritmos
empleados reportan varios modelos. De todos los modelos obtenidos, solo se
tuvieron en cuenta aquellos que cumplieran con el criterio de la sección 3.1.2,
usando ![]() .
.
4.1.1 Búsqueda exacta conformacional
Un detalle importante de la búsqueda exacta es que, si bien siempre encuentra al conjunto de descriptores que mejor ajuste a los valores experimentales de las moléculas que se estudia, no dice nada respecto del poder predictivo de los modelos obtenidos. Esto se debe a que se prueban todas las combinaciones de confórmeros posibles, pero no se dispone de un criterio para elegir los confórmeros que se usarán en el conjunto de validación, y por lo tanto dicho conjunto no se puede definir. Por esta razón, este método solo es útil para evaluar cómo ajustan los otros métodos solo al conjunto de calibración.
Los resultados de la búsqueda exacta conformacional se muestran en la tabla 6 .
En todos los casos, se aplicó SI sobre el conjunto de confórmeros de mínima energía.
El método RM se usó como punto de partida de varios de nuestros algoritmos, y es el método más usado por nuestro grupo de trabajo[?, ?]. Por este motivo, resulta clave utilizarlo en todos los conjuntos para luego poder compararlo con los nuevos algoritmos, y analizar si efectivamente se realizó una mejora en la metodología aplicada.
En este Trabajo de
Tesina, se empleó una versión modificada de RM, que toma en cuenta al parámetro
![]() .
.
A menos que se
especifique lo contrario, la matriz ![]() �sobre la cual
se aplicó RM es la correspondiente al conjunto de confórmeros de mínima
energía.
�sobre la cual
se aplicó RM es la correspondiente al conjunto de confórmeros de mínima
energía.
Como describimos
anteriormente, CRM consiste en la aplicación del Método de Reemplazo a la
matriz ![]() �definida en la
sección 3.3. Con el objetivo de obtener más modelos y garantizar que los mismos
no sobreajusten con el conjunto de calibración, se aplicó RM sobre las
siguientes submatrices por separado:
�definida en la
sección 3.3. Con el objetivo de obtener más modelos y garantizar que los mismos
no sobreajusten con el conjunto de calibración, se aplicó RM sobre las
siguientes submatrices por separado:
� ![]()
� ![]()
� ![]()
� ![]()
� ![]()
� ![]()
� ![]()
� ![]()
� ![]()
�Los resultados reportados son los del mejor modelo obtenido a través de la exploración de cualquiera de las matrices mencionadas anteriormente.
En todos los conjuntos,
el método CS se aplicó usando ![]() .
.
A modo de reflejar con
mayor claridad los principales resultados obtenidos con la aplicación de los
métodos estudiados, se presentan los mismos en formato de tablas. En todos los
casos, a excepción del cuadro 6, se reporta ![]() �y
�y ![]() �del modelo más
predictivo obtenido por el algoritmo dentro del rango de porcentajes definido
por
�del modelo más
predictivo obtenido por el algoritmo dentro del rango de porcentajes definido
por ![]() .
.
|
2*Método |
|
|
|
|
|
|
|
SI (mínimaenergía) |
�0,49 |
�0,37 |
|
�CS |
�0,32 |
�0,12 |
|
�RM (mínimaenergía) |
�0,46 |
�0,16 |
|
Exacto (mínimaenergía) |
�0,46 |
�0,16 |
|
Exacto |
�0,12 |
�0,02 |
Tabla 4.2.1: Resultados
de las pruebas realizadas en el conjunto CR
[HLE]
|
� 2*Algoritmo |
|
|
|
|||
|
|
|
|
|
|
|
|
|
SI |
�1,19 |
�1,07 |
�0,99 |
�1,12 |
�0,89 |
�1,09 |
|
�CS |
�1,19 |
�1,07 |
�1,09 |
�0,93 |
�0,95 |
�0,89 |
|
�RM |
�1,19 |
�1,07 |
�1,03 |
�0,92 |
�0,95 |
�0,87 |
|
�CRM |
�1,26 |
�1,02 |
�1,04 |
�0,82 |
�0,87 |
�0,82 |
� [HLE(20)]
|
2*Algoritmo |
|
|
|
|||
|
|
|
|
|
|
|
|
|
SI |
�1,23 |
�1,15 |
�1,06 |
�1,00 |
�0,96 |
�1,03 |
|
�CS |
�1,23 |
�1,15 |
�1,09 |
�0,88 |
�0,94 |
�0,93 |
|
�RM |
�1,23 |
�1,15 |
�1,09 |
�0,91 |
�1,02 |
�0,89 |
|
�CRM |
�1,23 |
�1,06 |
�1,06 |
�0,85 |
�0,98 |
�0,86 |
� [HLE2]
|
2*Algoritmo |
|
|
|
|||
|
|
|
|
|
|
|
|
|
SI |
�1,06 |
�1,61 |
�0,89 |
�1,71 |
�0,77 |
�1,51 |
|
�CS |
�1,04 |
�1,45 |
�0,89 |
�1,31 |
�0,75 |
�1,21 |
|
�RM |
�1,00 |
�1,35 |
�0,91 |
�1,25 |
�0,76 |
�1,15 |
|
�CRM |
�1,00 |
�1,35 |
�0,92 |
�1,21 |
�0,75 |
�1,12 |
Tabla 4.2.2: Resultados de las pruebas realizadas sobre los conjuntos basados en HLE.
[CatG]
|
� 2*Algoritmo |
|
|
|
|||
|
|
|
|
|
|
|
|
|
SI |
�0,74 |
�0,91 |
�0,68 |
�0,91 |
�0,63 |
�0,80 |
|
�CS |
�0,76 |
�0,74 |
�0,63 |
�0,65 |
�0,49 |
�0,67 |
|
�RM |
�0,78 |
�0,75 |
�0,72 |
�0,68 |
�0,62 |
�0,67 |
|
�CRM |
�0,78 |
�0,68 |
�0,64 |
�0,51 |
�0,61 |
�0,57 |
� [CatG(20)]
|
2*Algoritmo |
|
|
|
|||
|
|
|
|
|
|
|
|
|
SI |
�0,75 |
�0,83 |
�0,68 |
�0,89 |
�0,61 |
�0,95 |
|
�CS |
�0,71 |
�0,79 |
�0,63 |
�0,63 |
�0,59 |
�0,65 |
|
�RM |
�0,78 |
�0,74 |
�0,71 |
�0,73 |
�0,66 |
�0,72 |
|
�CRM |
�0,78 |
�0,67 |
�0,68 |
�0,56 |
�0,55 |
�0,48 |
� [CatG2]
|
2*Algoritmo |
|
|
|
|||
|
|
|
|
|
|
|
|
|
SI |
�0,73 |
�0,92 |
�0,65 |
�0,83 |
�0,57 |
�0,91 |
|
�CS |
�0,70 |
�0,72 |
�0,60 |
�0,70 |
�0,52 |
�0,72 |
|
�RM |
�0,86 |
�0,77 |
�0,69 |
�0,72 |
�0,61 |
�0,72 |
|
�CRM |
�0,73 |
�0,69 |
�0,68 |
�0,63 |
�0,48 |
�0,70 |
Tabla 4.2.3: Resultados de las pruebas realizadas sobre
los conjuntos basados en CatG.
[PR3]
|
� 2*Algoritmo |
|
|
|
|||
|
|
|
|
|
|
|
|
|
SI |
�0,92 |
�1,24 |
�0,78 |
�1,21 |
�0,69 |
�1,12 |
|
�CS |
�0,95 |
�1,09 |
�0,70 |
�0,94 |
�0,61 |
�0,99 |
|
�RM |
�1,05 |
�1,05 |
�0,80 |
�0,96 |
�0,72 |
�0,91 |
|
�CRM |
�0,97 |
�0,91 |
�0,80 |
�0,85 |
�0,67 |
�0,89 |
[PR3(20)]
|
2*Algoritmo |
|
|
|
|||
|
|
|
|
|
|
|
|
|
SI |
�0,96 |
�1,19 |
�0,81 |
�1,11 |
�0,74 |
�1,10 |
|
�CS |
�0,66 |
�0,97 |
�0,72 |
�0,91 |
�0,66 |
�0,97 |
|
�RM |
�1,03 |
�1,03 |
�0,81 |
�1,01 |
�0,66 |
�0,99 |
|
�CRM |
�1,01 |
�0,96 |
�0,77 |
�0,88 |
�0,65 |
�0,85 |
� [PR3-2]
|
2*Algoritmo |
|
|
|
|||
|
|
|
|
|
|
|
|
|
SI |
�0,89 |
�1,05 |
�0,76 |
�1,16 |
�0,68 |
�1,14 |
|
�CS |
�0,93 |
�0,94 |
�0,81 |
�0,86 |
�0,75 |
�0,93 |
|
�RM |
�0,88 |
�0,89 |
�0,71 |
�0,87 |
�0,59 |
�1,03 |
|
�CRM |
�0,88 |
�0,84 |
�0,76 |
�0,81 |
�0,74 |
�0,78 |
Tabla 4.2.4: Resultados de las pruebas realizadas sobre los conjuntos basados en PR3.
[Angio]
|
� 2*Algoritmo |
|
|
|
|||
|
|
|
|
|
|
|
|
|
SI |
�1,03 |
�1,73 |
�0,88 |
�1,85 |
�0,78 |
�2,42 |
|
�CS |
�1,05 |
�1,39 |
�0,85 |
�1,25 |
�0,79 |
�1,31 |
|
�RM |
�1,12 |
�1,26 |
�1,02 |
�1,32 |
�0,83 |
�1,52 |
|
�CRM |
�1,16 |
�1,20 |
�0,99 |
�1,25 |
�0,80 |
�1,48 |
� [Angio(20)]
|
2*Algoritmo |
|
|
|
|||
|
|
|
|
|
|
|
|
|
SI |
�1,04 |
�1,42 |
�0,88 |
�1,67 |
�0,79 |
�1,96 |
|
�CS |
�1,04 |
�1,38 |
�0,87 |
�1,42 |
�0,66 |
�1,58 |
|
�RM |
�1,17 |
�1,19 |
�0,98 |
�1,38 |
�0,83 |
�1,54 |
|
�CRM |
�1,20 |
�1,19 |
�0,92 |
�1,32 |
�0,86 |
�1,65 |
� [Angio2]
|
2*Algoritmo |
|
|
|
|||
|
|
|
|
|
|
|
|
|
SI |
�1,09 |
�1,66 |
�0,94 |
�1,83 |
�0,83 |
�1,84 |
|
�CS |
�1,15 |
�1,19 |
�0,66 |
�1,25 |
�0,55 |
�1,80 |
|
�RM |
�1,15 |
�1,15 |
�0,99 |
�1,29 |
�0,78 |
�1,34 |
|
�CRM |
�1,25 |
�1,01 |
�1,06 |
�1,01 |
�0,72 |
�1,29 |
Tabla 4.2.5: Resultados de las pruebas realizadas sobre los conjuntos basados en Angio.
� De todos los conjuntos ensayados, aquellos basados en Angio (con mayor diversidad estructural) reflejan más la diferencia estadística entre los métodos desarrollados.
� La búsqueda exacta conformacional realizada muestra que hay conjuntos que ajustan mucho mejor a la propiedad estudiada que el conjunto de mínima energía (ver tabla 6); esto implica que nuestros esfuerzos por encontrar la manera de elegir el conjunto de confórmeros más representativo son justificables.
� CS es un algoritmo que elige distintos
conjuntos de confórmeros para hacer las regresiones. En las tablas 7 a 10 se
puede apreciar que, en la mayoría de los casos, CS ajusta mucho mejor que los
demás métodos al conjunto de calibración. Sin embargo, esto no ocurre con el
conjunto de validación; se puede apreciar que en algunos casos el valor de ![]() �es menor que
aquel obtenido mediante RM, mientras que en otros casos es mayor. Por otra
parte, todos los modelos obtenidos son mucho más predictivos que aquellos que
se obtienen mediante SI.
�es menor que
aquel obtenido mediante RM, mientras que en otros casos es mayor. Por otra
parte, todos los modelos obtenidos son mucho más predictivos que aquellos que
se obtienen mediante SI.
� Para obtener modelos que eligen al conjunto de confórmeros más representativos, fue necesario definir distintos criterios de selección, ya que si no se dispone de los mismos no hay manera de seleccionar los confórmeros de las moléculas que forman parte del conjunto de validación y/o de un nuevo conjunto cuyas propiedades se quieren predecir.
� El algoritmo CRM permite obtener, en
todos los casos, modelos más predictivos que cuando se aplica RM al conjunto de
menor energía (poseen menor valor de ![]() ); esta propiedad se verifica de forma homogénea en
todos los conjuntos estudiados. Esto implica que la matriz
); esta propiedad se verifica de forma homogénea en
todos los conjuntos estudiados. Esto implica que la matriz ![]() �definida en la
sección 3.3 describe mejor a los sistemas químicos estudiados que
�definida en la
sección 3.3 describe mejor a los sistemas químicos estudiados que ![]() .
.
� En la práctica, se recomienda aplicar CRM
como punto de partida, y luego aplicar CS para ver si es posible mejorar los
resultados.
Bibliografía
[1] C. Hansch y A. Leo. Exploring QSAR. Fundamentals and Applications in Chemistry and Biology. American Chemical Society, 1995.
[2] H. Kubinyi. QSAR: Hansch Analysis and Related Approaches.Wiley-Interscience, 2008.
[3] A.R.Katritzky,V.S.Lobanov,yM.Karelson. Qspr:the correlation and quantitative prediction of chemical andphysical properties from structure. Chemical Society Reviews, 24:279-287, 1995.
[4] M. A. Lill. Multi-dimensional qsar in drug discovery. Drug Discovery Today, 12(23/24):1013-1017, Diciembre 2007.
[5] L. B. Kier y L. H. Hall. Molecular Structure Description, The electrotopological state. Academic Press, 1999.
[6] M. V. Diudea, editor. QSPR/QSAR Studies by Molecular Descriptors. Nova Science Publishers, Inc., 2001.
[7] R. Todeschini, P. Gramatica, R. Provenzani, y E. Marengo. Weighted holistic invariant molecular descriptors. part 2. theory development and applications on modeling physicochemical properties of polyaromatic hydrocarbons. Chemometrics� and Intelligent Laboratory� Systems, 27:221-229, 1995.
[8]� E-dragon. http://www.vcclab.org/lab/edragon/.
[9] Recon. http://www.drugmining.com.
[10] Coral. http://www.insilico.eu/coral.
[11] Codessa. http://ufark12.chem.ufl.edu.
[12]� http://www.dddmag.com/qsar-prediction-beyond-the-fourth.aspx.
[13]� E.Vicente,P.R.Duchowicz, E. V. Ortiz, A.Monge, yE. A. Castro. Exploring 3-arylquinoxaline-2-carbonitrile1,4-di-n-oxidesactivities against neglecteddiseases with QSAR. Chemical Biology and Drug Design, 76:59-69, 2010.
[14] A. G. Mercader, P. R. Duchowicz, F. M. Fernández, y E. A. Castro. Advances in the replacement and enhanced replacement method in QSAR and QSPR theories. Journal of Chemical Information and Modeling, 51:1575-1581, 2011.
[15] P. R. Duchowicz. Aplicaciones fisicoquímicas y biológicas de la teoría QSPR-QSAR. Tesis Doctoral, Universidad Nacional de La Plata, 2005.
[16] J O. Rawlings, S.G. Pantula, y D.A. Dickey. Applied Regression Analysis: A Research Tool. Springer, 2da edición, 1998.
[17] H. M. Badawi, M. A. A. Al-Khaldi, Z. H. A. Al-Sunaili, y S. S. A. Al-Abbad. Conformational properties and vibrational analyses of monomeric pentafluoropropionic acid CF3CF3COOH and pentafluoropropionamide CF3CF4CONH2. Canadian Journalof analytical Sciences and Spectroscopy, 5:252-269, 2007.
[18] E. H. Cutín, C. O. Della Védova, H.-G. Mack, y H. Oberhammer. Conformation and gas-phase structure of difluorosulphenylimine cyanide, F2S(O)NCN. Journal of Molecular Structure, 354:165-168, 1995.
[19] Hyperchem v6.0. http://www.hyper.com/News/pressRelease/Release60Feb2000/tabid/411/Default.aspx.
[20] F. Jensen. Introduction to Computational Chemistry. John Wiley & Sons, Ltd, 2007.
[21] Hypercube Inc. HyperChem Release 7, Enero 2002.
[22] Open babel. openbabel.org.
[23] Xmacro. http://xmacro.sourceforge.net/.
[24] Gnu bourne again shell. www.gnu.org/s/bash/.
[25] J. Garcia, P. R. Duchowicz, M. F. Rozas, J. A. Caram, M. V. Mirífico, F. M. Fernández, y E. A. Castro. A comparative qsar on 1,2,5-thiadiazolidin-3-one 1,1-dioxide compounds as selective inhibitors of human serine proteinases. Journal of Molecular Graphics and Modelling, 31:10-19, 2011.
[26] I. B. Bersuker, S. Bah�eci,y J. E. Boggs. Improved electron-conformational� method of pharmacophore� identification and bioactivity prediction. application to angiotensin converting enzyme inhibitors. Journal of Chemical Information and Computational� Science, 40:1363-1376, 2000.
[27] A. L. Kierszenbaum. Histology and cell biology: an introduction to pathology. Mosby Elsevier, 2007.
[28] W.� C. Groutas, R.� Kuang, R. Venkataraman,� J. B. Epp, S. Ruan, y O. Prakash. Structure-based design of a general class of mechanism-based inhibitors of the serine proteinases employing a novel amino acid-derived heterocyclic scaffold. Bochemistry, 36:4739-4750, 1997.
[29] R. Dhami, B. Gilks, C. Xie, K.Zay,J. L. Wright, y A. Churg. Acute cigarette smoke-induced connective tissue breakdown is mediated by neutrophils and prevented by 1-antitrypsin. American Journal of Respiratory Cell and Molecular Biology, 22:244-252, 2000.
[30] R. A. Stockley. The role of proteinases in the pathogenesis of chronic bronchitis. American Journal of Respiratory and Critical Care Medicine, 150:S109-S113, 1994.
[31] P. J. Barnes. Novel approaches and targets for treatment of chronic obstructive pulmonary disease. Respiratory and Critical Care Medicine, 160:S72-S79, 1999.
[32] J. F. Morrison y C. T. Walsh. The behavior and significance of slow-binding enzyme inhibitors. Advanced Enzymology, 61:201-301, 1988.
[33] Matlab. www.mathworks.com/products/matlab/.
[34] A. Talevi, M. Goodarzi, E. V. Ortiz, P. R. Duchowicz, C. L. Bellera, G. Pesce, E. A. Castro, y L. E. Bruno-Blanch. Prediction of drug intestinal absorption by new linear and nonlinear QSPR. European Journal of Medicinal Chemistry, 46:218-228, 2011.
[35] E. Ibezim, P. R. Duchowicz, E. V. Ortiz, y E. A. Castro. QSAR on aryl-piperazine derivatives with activity on malaria. Chemometrics and Intelligent Laboratory Systems, 110:81-88, 2012.
| Este apunte fue enviado por su autor en formato DOC (Word).
Para poder visualizarlo correctamente (con imágenes, tablas, etc) haga click aquí o aquí si desea abrirla en ventana nueva. |
Comentarios de los usuarios
Agregar un comentario:
Aún no hay comentarios para este recurso.
Boletín de Novedades

Acceso rápido
• Monografias
• Examenes
• Enlaces
• Publicar material o sitio
• Foros
• Diversion
• Test de Orientacion
• Institutos
• Secundarios
• Universidades de Argentina
• Residencias Universitarias
• Guia de Carreras Universitarias y Cursos
• Cultura del Mundo
• Buscador en tu sitio


Sobre ALIPSO.COM
Monografias, Exámenes, Universidades, Terciarios, Carreras, Cursos, Donde Estudiar, Que Estudiar y más: Desde 1999 brindamos a los estudiantes y docentes un lugar para publicar contenido educativo y nutrirse del conocimiento.
Contacto »Legales